
5 min read time

Today’s consumer insights teams face a unique challenge.
10-20 years ago, sourcing consumer data was one of the key issues. Now, brands are inundated with data, so the more pressing challenge is being able to differentiate between what is important to pay attention to and what is just noise.
In times like these, when budgets are tight and resources thin, consumer insight departments cannot risk providing brand teams with potentially misleading information to make decisions on.
That’s why we’re here to help. In this blog, you’ll find 5 tips to help you ensure you’re getting the right data that’s as robust as it can possibly be.
When looking at your sampling methods, ask yourself:
A robust sample size is necessary to ensure you’re gaining a true representation of your consumers.
If the pool of people you’re surveying isn’t large enough, it will be dangerous for you to draw conclusions from your data. When a sample size isn’t robust, there’s always the risk of your results being skewed by outliers in your data.
Traditional Market Research firms collect large samples on an infrequent basis. These can range from 200 – 5,000 people depending on the nature of the research and the budget for the project.
This static form of data capture may have been enough 10-20 years ago, but it cannot match up to the fast-paced, changing habits of today’s consumers. This is why we’re seeing leading brands move towards real-time data sources.
These sample sizes may be smaller initially, but they benefit from cumulative growth, as the data is collected every day and is therefore constantly evolving in line with changing consumer needs.
An advantage of real-time is that you get the same volume of people over the same period as a static dip, but you also get to speak to these people continuously during that period. Because of this, you get a more accurate read on how consumers feel about your brand so you can more easily attribute your scores to either the marketing you were doing at the time or the external context surrounding your brand.

You’ll need to be surveying enough of the right people to ensure the sample you collect is representative of the population you are interested in.
It’s no good speaking to 500 people every day if these people will never consider your product, but similarly you can’t grow if you don’t understand your non-users.
The trick here is not to go too narrow or too broad. It’s a little like Goldilocks and her pursuit for a bed that’s just right.
For longer-term understanding it is best to ensure that you capture people who are interested in your category but haven’t purchased it yet, people who have purchased a competitive brand in your category (Non-Users) and people who have purchased your brand (Users).
In terms of demographics, be wary of focusing too much on your current target market, as this might hide opportunities for later expansion.
It is tempting to zero in on surveying who you currently think of as your ideal customer. While this is useful for product feedback, it can lead to bias at a wider scale.
Understanding the incentive of your respondents is incredibly important. You can start by looking into how these people are sourced. Low-cost respondents are often incentivized to get through surveys.
If you are aware of this up-front, you can put measures in place to help you distinguish between authentic respondents and those looking to game the system.
The most common ways to game the system include:
You’ll be familiar with Kahneman’s System 1 and 2 approach.
But how does this relate back to the quality of your data?
Well, if you know that 95% of decisions are made via System 1 (our feelings) and are later justified by our thoughts (System 2), you can use this to your advantage.
Behavioral Science has proven that feelings precede actions. With that in mind, it’s imperative to measure consumer feelings first, while also understanding how they justify their actions, second.
To understand how MarTech platforms are embedding instinctive gut feelings into their methodologies, click here.

It’s impossible to eradicate data bias completely but the trick to removing as much as possible is to put processes in place to minimize its impact.
This is why the set-up of your data is so important.
Here are 2 things to check before you start sampling consumers:
It’s easy to make mistakes about which elements will change during your sampling and which will stay the same.
For instance, you might segment competitors by revenue size like “small”, “medium” or “large”. The problem is that this can change over time which means you might end up with difficulty if you assume that these elements are fixed.
When in doubt, add dates to the elements you want to track over time.
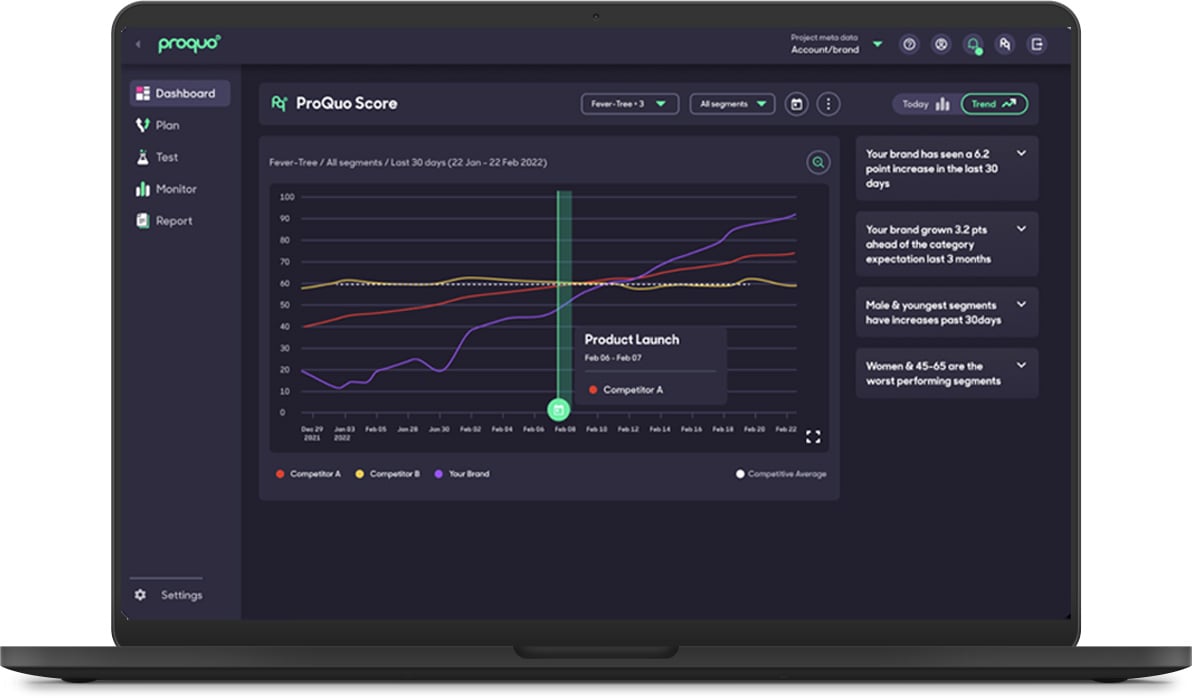
Establishing a realistic expectation of how you believe your data will change over time will help you to reduce bias.
This is because these predictions will enable you to notice anomalies or errors within your data, as you will have an idea of what you expect to see.
The best way to create these predictions is via trusted statistical models.
Insights teams commonly use frequentist data models to establish expectations. This may involve simply calculating averages and confidence , but in more sophisticated applications may also include developing time series models which can forecast changes into the future.
The leading edge of this kind of forecasting uses Bayesian methods to fit time series models, which also take into account changes in inputs to the system, allowing us to be more accurate about the uncertainty of the predictions.
As humans, we’re used to evaluating our successes based on the outcome we see.
Yet, the most accurate way of determining success isn’t through one number, it’s through understanding the process involved in getting to that number.
Only after embedding a contextual system into your interactions and data will you be able to fully understand - and create thoughtful insights - out of the numbers in front of you.
This is why real-time data is now a must-have in marketing.
Real-time data accounts for context, where traditional data sources cannot.
Let’s think about this in the context of a marketing dip. These dips are only capable of capturing one moment in time, which makes the data really difficult to use for accurate analyses or comparisons.
Even when you conduct two different dips, it can get messy. It’s hard to see differences between dips as the research is gathered at a single point in time. Because of this, it can look like nothing has changed when in fact there could have been a period of serious momentum, followed by serious declines in the time periods between your recorded points.
When you compare this to real-time data, which speaks to consumers, brands, and competitors, every day – you can see why periodic sampling just can’t add up.
If your data is constantly evolving, is gathered in real-time, has a method of actively removing bias within the survey process, and collects implicit thoughts and feelings, you’re already miles ahead of the pack.
On ProQuo AI’s live consumer intelligence platform, we do all four of these things.
In addition to real-time data, you also get:
To find out more about ProQuo’s data, click here.
Quick links
![]()
© 2020-2023 ProQuo AI International
All rights reservedWebsite by Blend